NiFi and Friends
FLaNK Extended Stack
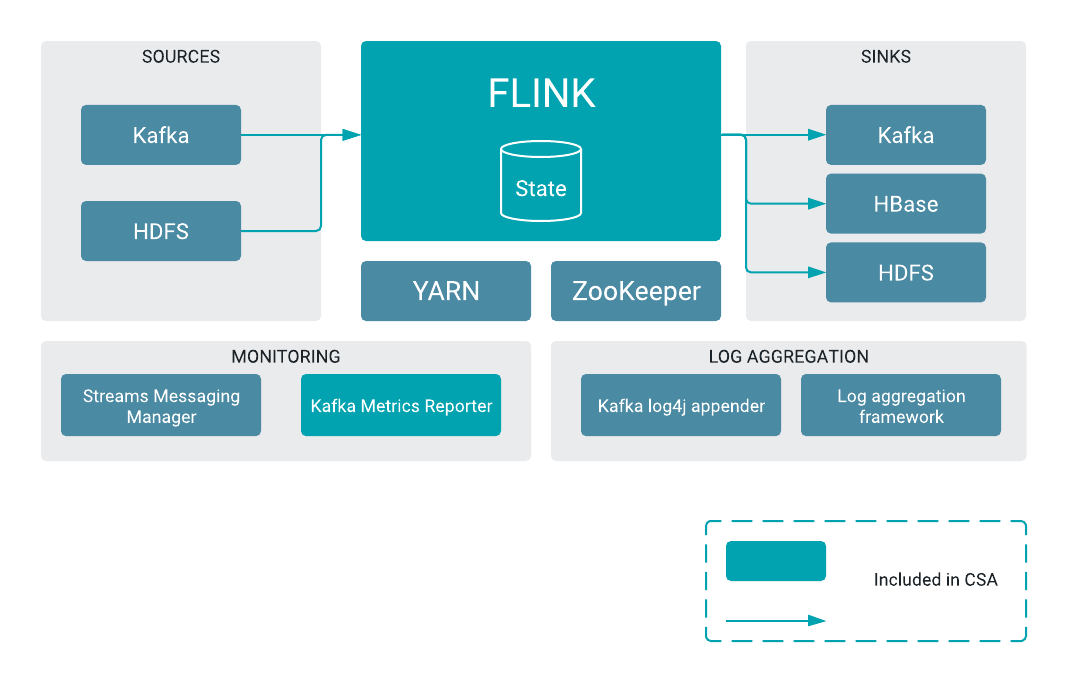
FLaNK Extended Stack
Note:
All of these ports can be changed by administrators or in version updates. Also if you are running Apache Knox like in Cloudera Data Platform Public Cloud, these ports may be changed or hidden. This is just based on a version of CDF I am running and defaults in. This does not include standard Cloudera ports for Cloudera Manager, Hadoop, Atlas, Ranger and other necessary and fun services.
Cloudera Flow Management (CFM Powered by Apache NiFi)
- Cloudera NiFi HTTP: 8080 or 9090
- Cloudera NiFi HTTPS: 8443 or 9443
- Cloudera NiFi RIP Socket: 10443 or 50999
- Cloudera NiFi Node Protocol: 11443
- Cloudera NiFi Load Balancing: 6342
- Cloudera NiFi Registry: 18080
- Cloudera NiFi Registry SSL: 18433
- Cloudera NiFi Certificate Authority: 10443
Cloudera Edge Flow Management (CEM Powered by Apache NiFi - MiNiFi)
- Cloudera EFM HTTP: 10080
- Cloudera EFM CoAP: 8989
Cloudera Stream Processing (CSP Powered by Apache Kafka)
- Cloudera Kafka: 9092
- Cloudera Kafka SSL: 9093
- Cloudera Kafka Connect: 38083
- Cloudera Kafka Connect SSL: 38085
- Cloudera Kafka Jetty Metrics: 38084
- Cloudera Kafka JMX: 9393
- Cloudera Kafka MirrorMaker JMX: 9394
- Cloudera Kafka HTTP Metric: 24042
- Cloudera Schema Registry Registry: 7788
- Cloudera Schema Registry Admin: 7789
- Cloudera Schema Registry SSL: 7790
- Cloudera Schema Registry Admin SSL: 7791
- Cloudera Schema Registry Database (Postgresql): 5432
- Cloudera SRM: 6669
- Cloudera RPC: 8081
- Cloudera SRM Rest: 6670
- Cloudera SRM Rest SSL: 6671
- Cloudera SMM Rest / UI: 9991
- Cloudera SMM Manager: 8585
- Cloudera SMM Manager SSL: 8587
- Cloudera SMM Manager Admin: 8586
- Cloudera SMM Manager Admin SSL: 8588
- Cloudera SMM Service Monitor: 9997
- Cloudera SMM Kafka Connect: 38083
- Cloudera SMM Database (Postgresql): 5432
Cloudera Streaming Analytics (CSA Powered by Apache Flink)
- Cloudera Flink Dashboard: 8082
References
- https://docs.cloudera.com/HDPDocuments/HDF3/HDF-3.5.0/nifi-configuration-best-practices/content/nifi.html
- https://docs.cloudera.com/cem/1.1.1/installation/topics/cem-open-ports.html
- https://docs.cloudera.com/csa/1.1.0/overview/topics/csa-overview.html
- https://docs.cloudera.com/csp/2.0.1/deployment/topics/csp-configure-smm.html
- https://docs.cloudera.com/smm/2.0.0/upgrading-smm/topics/smm-upgrade-smm-server.html

































