30-April-2023
FLiPN-FLaNK Stack Weekly
Tim Spann @PaaSDev
It was great seeing everyone at the Real-Time Analytics Summit and the meetup in San Francisco. Now let's get current on NiFi and build some new Data Flows!
May 3, 2023!!!! Join me and the NiFi creators! https://attend.cloudera.com/nificommitters0503?internal_keyplay=data-flow&internal_campaign=FY24-Q2_Webinar_Cloudera_AMER_NiFi_Meet_the_Committers&cid=7012H000001ZNXBQA4&internal_link=p07
Cool NiFi 2.0 Stuff -> https://issues.apache.org/jira/browse/NIFI-10757

CODE + COMMUNITY
Please join my meetup group NJ/NYC/Philly/Virtual.
http://www.meetup.com/futureofdata-princeton/
https://www.meetup.com/futureofdata-sanfrancisco/events/292453316/
https://www.meetup.com/futureofdata-newyork/
https://www.meetup.com/futureofdata-philadelphia/
This is Issue #81
https://github.com/tspannhw/FLiPStackWeekly
https://www.linkedin.com/pulse/schedule-2023-tim-spann-/
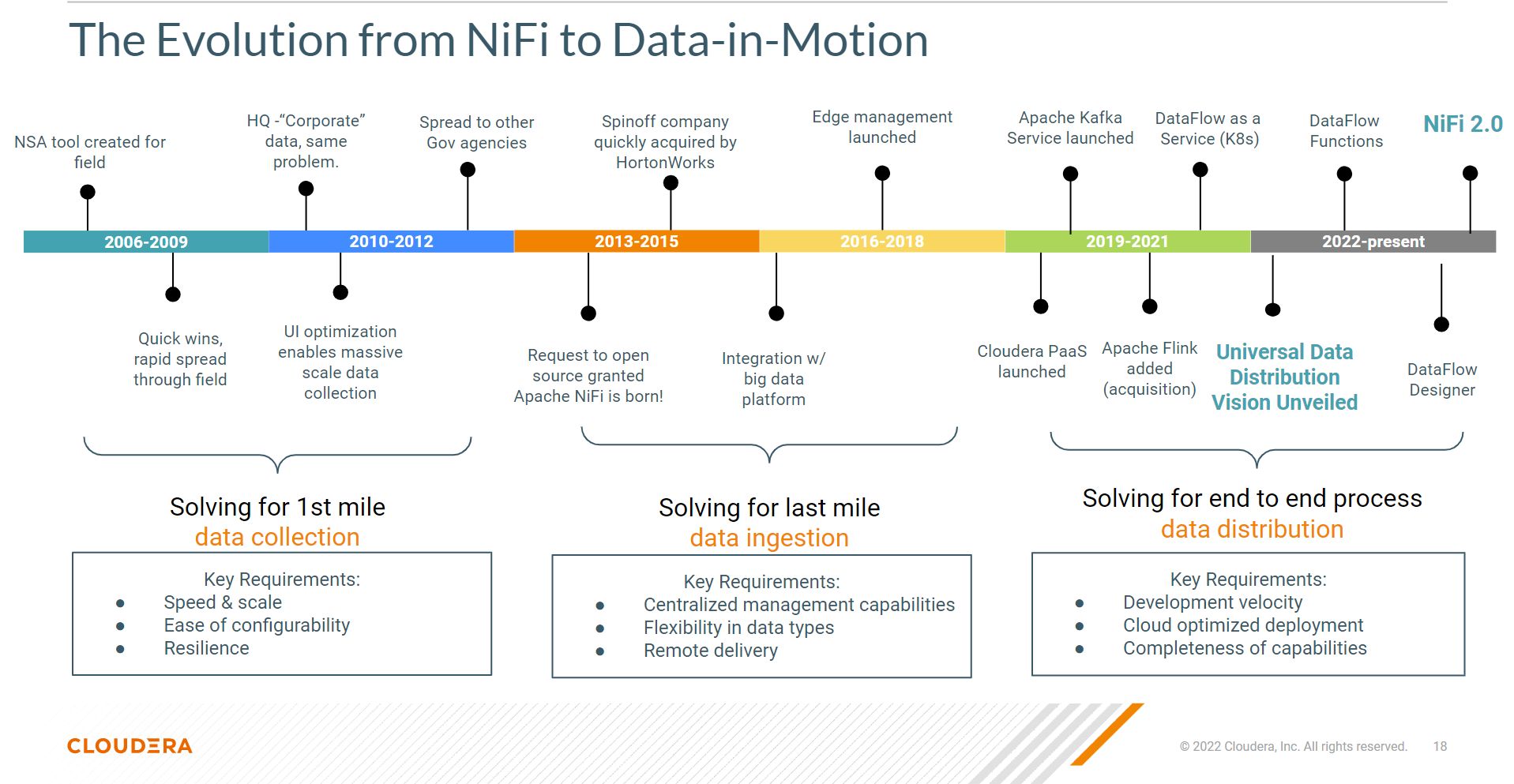
Apache NiFi 2.0
NiFi 2.0 Python Demo
NiFi build for 2.0.0-SNAPSHOT allowing Python Processors: https://drive.google.com/file/d/1xAuao9rV8F_CQBLqWLWp7P12iZpuuUEP/view?usp=share_link And some sample processors: https://drive.google.com/drive/folders/1VCtNQmThAHL44-t2ORdav9YPIHMvCk_b
https://www.youtube.com/watch?v=9Oi_6nFmbPg&ab_channel=NiFiNotes
MiNiFi Updates
CEM MiNiFi C++ Agent - 1.23.04: Added support for the following processors: Fetch/PutOPCProcessor to get and push data over OPC-UA, Start shipping prometheus extension for metrics export, EL toDate can now parse RFC3339 dates. https://docs.cloudera.com/cem/1.5.1/release-notes-minifi-cpp/topics/cem-minifi-cpp-agent-updates.html https://docs.cloudera.com/cem/1.5.1/release-notes-minifi-cpp/topics/cem-minifi-cpp-download-locations.html
Data Trends
https://www.thoughtworks.com/radar/languages-and-frameworks?blipid=202210050
https://github.com/sdv-dev/SDV
Videos
https://www.youtube.com/watch?v=lqxPyHYzGQ0&ab_channel=DatainMotion
https://www.youtube.com/watch?v=4RoMOQtqKC0
https://www.youtube.com/watch?v=yKFS8-A14Tg&ab_channel=DatainMotion
Articles
https://www.cloudera.com/solutions/dim-developer.html
https://www.datainmotion.dev/2023/04/cloudera-data-flow-readyflows.html
https://www.datainmotion.dev/2023/04/dataflow-processors.html
https://funnifi.blogspot.com/2023/04/transform-json-string-field-into-record.html
http://funnifi.blogspot.com/2023/04/using-jslttransformjson-alternative-to.html
https://streamnative.io/blog/introducing-oxia-scalable-metadata-and-coordination?
Recent Talks
https://www.slideshare.net/bunkertor/meetup-streaming-data-pipeline-development
https://www.slideshare.net/bunkertor/rtas-2023-building-a-realtime-iot-application
Events
https://www.youtube.com/watch?v=Ws7YmAHE1O8
https://www.cloudera.com/about/events/evolve.html
https://web.cvent.com/event/7598f981-2f7e-4915-b662-bd7be9b5f48d/summary?RefId=homepage_impact24
May 3, 2023: Meet the Committers. Virtual https://attend.cloudera.com/nificommitters0503
May 3-10, 2023: Special Once in a Lifetime Event. Virtual.

May 9, 2023: Garden State Java User Group. In-Person. New Jersey https://gsjug.org/. Modern Data Streaming Pipelines with Java, NiFi, Flink, Kafka. https://gsjug.org/meetings/2023/may2023.html https://www.meetup.com/garden-state-java-user-group/events/293229660/
May 10-12, 2023: Open Source Summit North America. Virtual https://events.linuxfoundation.org/open-source-summit-north-america/
May 17-18, 2023: IBM Event. Raleigh, NC.
May 23, 2023: Pulsar Summit Europe. Virtual https://pulsar-summit.org/


May 24-25, 2023: Big Data Fest. Virtual. https://sessionize.com/big-data-fest-by-softserve/
June 14: 12PM EDT Cloudera Now - Virtual https://www.cloudera.com/about/events/cloudera-now-cdp.html?internal_keyplay=ALL&internal_campaign=FY24-Q2_AMER_CNOW_Q2_WEB_EP_P07_2023-06-14&cid=7012H000001ZLmyQAG&internal_link=p07
June 26-28, 2023: NLIT Summit. Milwaukee.
https://www.fbcinc.com/e/nlit/default.aspx
June 28, 2023: NiFi Meetup. Milwaukee and Hybrid. https://www.meetup.com/futureofdata-princeton/events/292976004/

July 19, 2023: 2-Hours to Data Innovation: Data Flow https://www.cloudera.com/about/events/hands-on-lab-series-2-hours-to-data-innovation.html
October 18, 2023: 2-Hours to Data Innovation: Data Flow https://www.cloudera.com/about/events/hands-on-lab-series-2-hours-to-data-innovation.html
Cloudera Events https://www.cloudera.com/about/events.html
More Events: https://www.linkedin.com/pulse/schedule-2023-tim-spann-/
Code
https://flightaware.com/adsb/stats/site/180330
https://huggingface.co/chat/conversation/644b0761bde5eee46bf58eb2
https://github.com/streamnative/oxia
Tools
https://github.com/xdgrulez/kash.py
https://github.com/kuasar-io/kuasar/releases
https://github.com/jkfran/killport
https://github.com/StanfordBDHG/HealthGPT
https://github.com/dynobo/normcap
https://github.com/faustomorales/keras-ocr
https://github.com/gventuri/pandas-ai
https://github.com/termux/termux-app
https://www.youtube.com/watch?v=GsUKTs-J7jQ&ab_channel=DatainMotion
https://github.com/h2oai/h2o-llmstudio
https://github.com/sdv-dev/SDV
https://github.com/karpathy/nanoGPT
© 2020-2023 Tim Spann








































