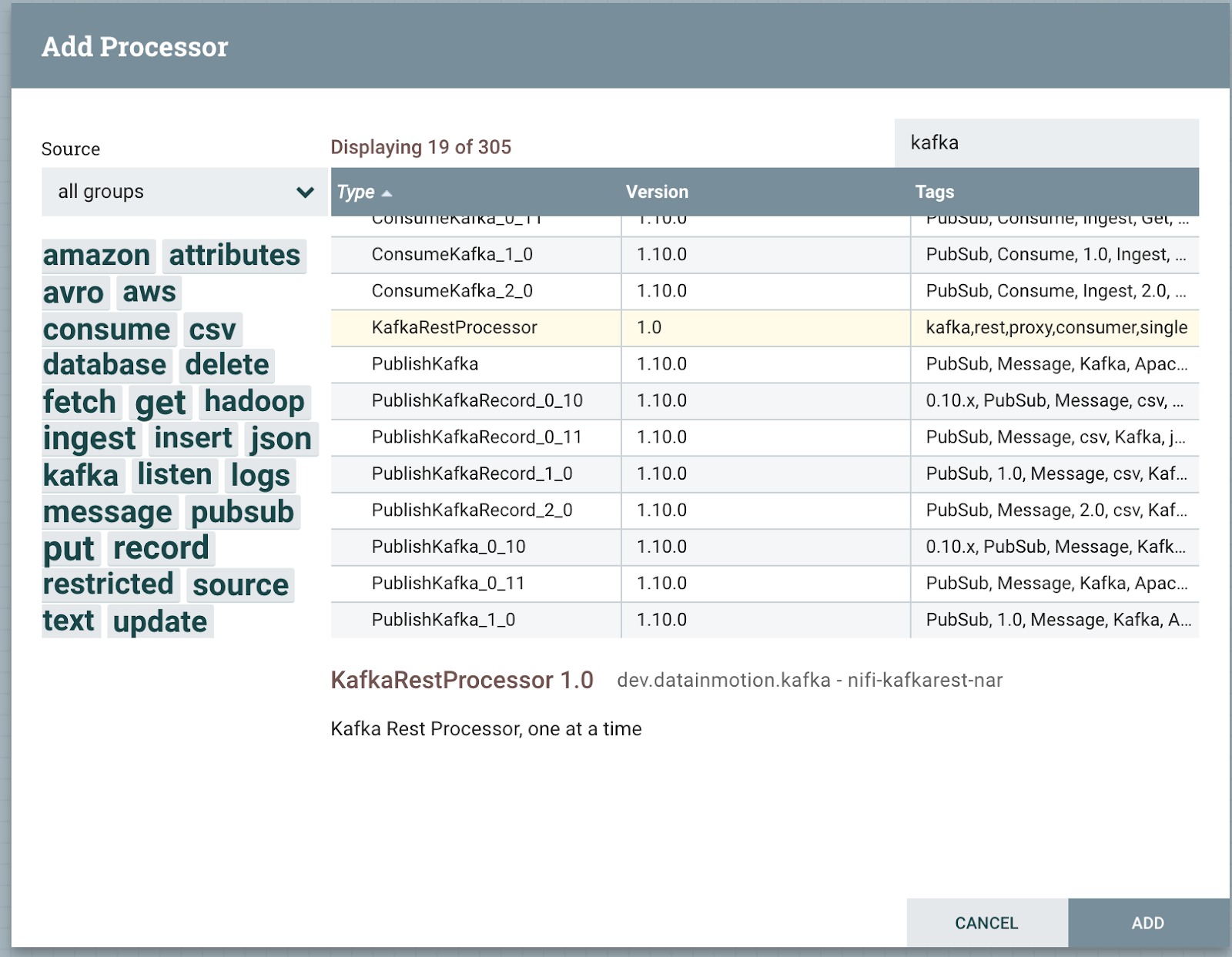
Writing a Custom Kafka Rest Proxy in 4 Hours
A custom processor for using NiFi as a REST Proxy to Kafka is very easy. So I made one in NiFi 1.10. It's a simple Kafka smart client that accepts POSTs, GETs or whatever HTTP request and returns a message from a Kafka topic, topic can be set via variables, HTTP request or your choice. To get on of the query parameters, you do so like this: ${http.query.param.topic}. I am using the plain old KafkaConsumer class.

If you need data, just CURL it or use your HTTP/REST client controls in Java, Python, Go, Scala, Ruby, C#, VB.NET or whatever.
curl http://localhost:9089?topic=bme680
Download a pre-built NAR and install. Note: this is a pre-release Alpha that I quickly built and tested on a few clusters. This is not an official project or product. This is a POC for myself to see how hard it could it be. It's not! Roll your own or join me in building out an open source project for one. What requirements do you have? This worked for me, send a curl, get a message.
Build a topic for Kafka with SMM in seconds

HandleHttpRequest (We could have hundreds of options here.
RouteOnAttribute

Provenance For An Example Kafka REST Call

To use the processor, we need to set some variables for Kafka Broker, Topic, Offset Reset, # of Records to grab at a time, Client Id, Group Id - important for keeping your offset, auto commit, deserializer for your key and value types - String is usually good, maybe Byte.

Kafka to HBase is Easy.

Kafka to Kudu is Easy.


Kafka Proxy Processor For Message Consumption Source
https://github.com/tspannhw/kafkarest-processor
Pre-Built NAR
https://github.com/tspannhw/kafkarest-processor/releases/download/0.1/nifi-kafkarest-nar-1.0.nar
Other Kafka Articles
- https://dev.to/tspannhw/migrating-apache-flume-flows-to-apache-nifi-kafka-source-to-http-rest-sink-and-http-rest-source-to-kafka-sink-1257
- https://dev.to/tspannhw/using-cloudera-streams-messaging-manager-for-apache-kafka-monitoring-management-analytics-and-crud-41fb
- https://dev.to/tspannhw/migrating-apache-flume-flows-to-apache-nifi-kafka-source-to-hdfs-kudu-file-hive-55gj
- https://dev.to/tspannhw/migrating-apache-flume-flows-to-apache-nifi-kafka-source-to-apache-parquet-on-hdfs-1npb
- https://dev.to/tspannhw/migrating-apache-flume-flows-to-apache-nifi-twitter-source-to-kafka-sink-31d1
- https://dev.to/tspannhw/migrating-apache-flume-flows-to-apache-nifi-syslog-to-kafka-3a1k
- https://dev.to/tspannhw/migrating-apache-flume-flows-to-apache-nifi-kafka-source-to-http-rest-sink-and-http-rest-source-to-kafka-sink-1257
- https://dev.to/tspannhw/using-grovepi-with-raspberry-pi-and-minifi-agents-for-data-ingest-to-parquet-kudu-orc-kafka-hive-and-impala-2h9k
- https://community.cloudera.com/t5/Community-Articles/Real-Time-Stock-Processing-With-Apache-NiFi-and-Apache-Kafka/ta-p/249221
- https://github.com/tspannhw/kafkaadmin-processor
- https://kafka.apache.org/22/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html
It's so easy, didn't wake the cat.





























































