2020 Events: https://www.linkedin.com/pulse/2020-streaming-edge-ai-events-tim-spann/
- August 13 - Industry Event - Including a FLaNK
- August 28 - 11:30-12:20 - Apache Beam Digital Summit
- https://2020.beamsummit.org/sessions/leukemia-early-detection-apache-beam/
- https://2020.beamsummit.org/speakers/timothy-spann/
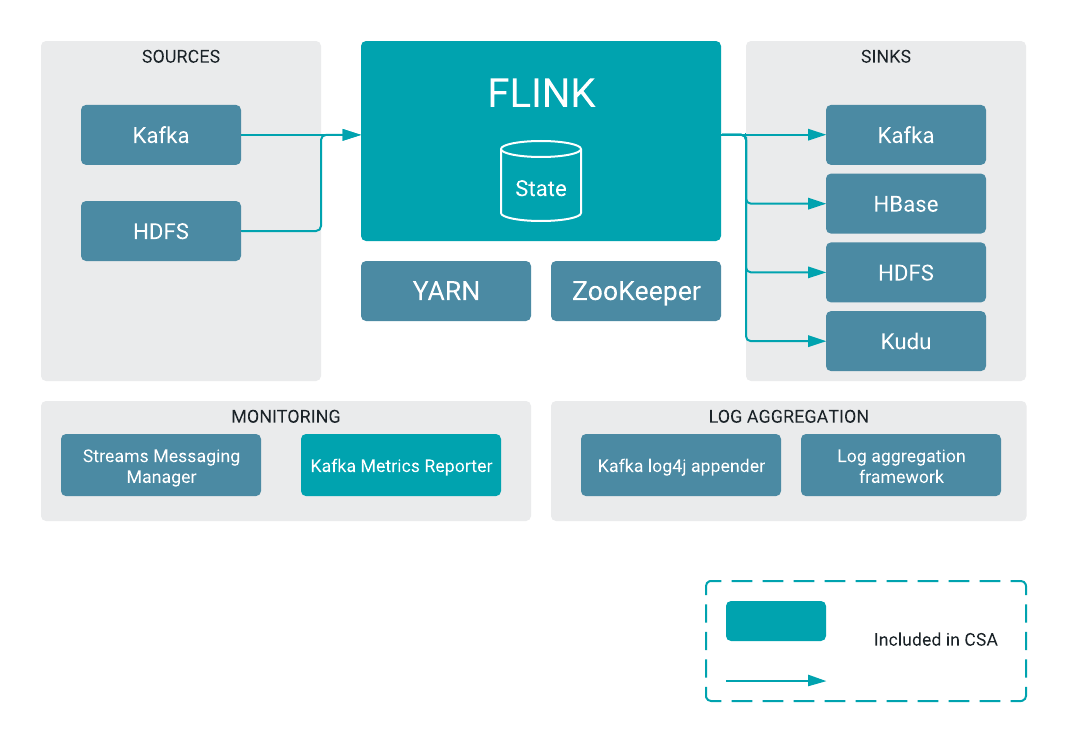
- Lightning Talk - Using the Mm FLaNK Stack for Edge AI (Flink, NiFi, Kafka, Kudu) 0.1
- September 16-17 - https://www.cloudera.com/about/events/cloudera-now-cdp.html
Sept 29 - Oct 1 - Apache Con https://apachecon.com/acna2020/
I have some talks here and I am bringing in some superstars to assist me! It's a dream team of speakers that I will be collaborate with. I will release names when we get closer. So I will be covering Apache MXNet, Apache NiFi, MiNiFi, Apache Flink, Apache Kafka, Apache Hue and Apache Kudu. I would be surprised if Apache Spark, Apache Hadoop, Apache Hive, Apache HBase, Apache Phoenix, Apache Zeppelin, Apache Livy
- Incrementally Streaming RDBMS Data to Your DataLake Automagically
- Apache Deep Learning 301
- Using the Mm FLaNK Stack for Edge AI (Apache MXNet, Apache Flink, Apache NiFi, Apache Kafka, Apache Kudu) 0.2
- Utilizing Apache NiFi and MiNiFi for EdgeAI IoT at Scale
- Edge to AI: Analytics from Edge to Cloud with Efficient Movement of Machine Data
- Real-Time Stock Processing With Apache NiFi, Apache Flink and Apache Kafka
- Sept 29 - Apache Streaming Meetup - https://www.meetup.com/futureofdata-princeton/events/272337950/ - Done and Recorded.
Overview: https://speakerdeck.com/tspannhw/2020-conference-talk-preview
October 9 - Ukraine DevOps Stage 2020 11am Ukraine Time - Apache NiFi Talk
https://www.datainmotion.dev/2020/05/cloudera-flow-management-101-lets-build.html
https://devopsstage.com/speakers/timothy-spann/
Oct 19 - 22. Flink Forward - Mm FLaNK Stack for Edge AI (Flink, NiFi, Kafka, Kudu)
Oct 22 - 1pm EST - https://www.flink-forward.org/global-2020/conference-program#using-the-mm-flank-stack-for-edge-ai--flink--nifi--kafka--kudu--
There's a few more coming this year, including Nethope, OSS and Big Data Conference.