Ingest Salesforce Data into Hive Using Apache Nifi
Ingest Salesforce Data into Hive Using Apache NiFi
TOOLS AND ACCOUNT USED:
Salesforce JDBC driver : https://www.progress.com/jdbc/salesforce
Java : 1.8.0_221
OSS: MacOS Mojave 10.14.5
SDFC Developer account: https://developer.salesforce.com/signup - 15 day trial
Reference Article : https://www.progress.com/tutorials/jdbc/ingest-salesforce-data-incrementally-into-hive-using-apache-nifi
Overall Flow :
Install Hive - Thrift, Metastore, and Hive Table schema that matches SDFC opportunity table.
Install NiFi - Add PutHive3streaming nar
Install and Configure Drivers : SalesforceConnect and Avroreader
Add Processors - QueryDatabaseTable and Puthive3Streaming
Install Salesforce JDBC and Hive drivers
java -jar PROGRESS_DATADIRECT_JDBC_SF_ALL.jar- Download DataDirect Salesforce JDBC driver from here.
- Download Cloudera Hive driver from here.
- To install the driver, execute the .jar package by running the following command in the terminal or just by double clicking on the jar package.
java -jar PROGRESS_DATADIRECT_JDBC_INSTALL.jar
Add Drivers to the Apache NiFi Classpath
Copy drivers
From - /home/user/Progress/DataDirect/Connect_for_JDBC_51/{sforce.jar,hive.jar}
To - /path/to/nifi/lib [/usr/local/Cellar/nifi/1.9.2/libexec/lib/
Restart Apache NiFi
Copy drivers
From - /home/user/Progress/DataDirect/Connect_for_JDBC_51/{sforce.jar,hive.jar}
To - /path/to/nifi/lib [/usr/local/Cellar/nifi/1.9.2/libexec/lib/
Restart Apache NiFi

Add and Configure the JDBC drivers
DBCPConnectionPool
AvroReader
DBCPConnectionPool
AvroReader
Add DBCPConnectionPool
Choose DBCPConnectionPool as your controller service
Add Properties below:
Database Connection URL = jdbc:datadirect:sforce://login.salesforce.com;SecurityToken=****
- NOTE below on SecurityToken
Choose DBCPConnectionPool as your controller service
Add Properties below:
Database Connection URL = jdbc:datadirect:sforce://login.salesforce.com;SecurityToken=****
- NOTE below on SecurityToken
- Database Driver Class Name : com.ddtek.jdbc.sforce.SForceDriver
- Database User - Developer account username
- Password - the Password for the Developer account
- Name - SalesforceConnect

Add Avro reader Controller :
This controller is used by the subsequent co-processor(PutHive3Streaming) to read Avro format data
from the previous processor(QueryDatabaseTable).
from the previous processor(QueryDatabaseTable).

Add and Configure Processors
QueryDatabaseTable
PutHive3Streaming
QueryDatabaseTable
To read the data from Salesforce use a processor called QueryDatabaseTable that supports
incremental data pull.
Choose QueryDatabaseTable and add it on to canvas as below.

Configure QueryDatabaseTable processor:
Right click on the QueryDatabaseTable, Choose scheduling type, manual or cron.
Under Properties tab and add following properties
Right click on the QueryDatabaseTable, Choose scheduling type, manual or cron.
Under Properties tab and add following properties
Database Connection Pooling Service : SalesForceConnect
Database Type : Generic
Table Name : Opportunity
Apply and save the processor configuration.
Apply and save the processor configuration.

PutHive3Streaming
NOTE: PutHivestreaming was used in the beginning, but for the downstream hive version 3.x
@Matthew Burgess recommended to use PutHive3Streaming processor.
Download it separately and add it to NiFi/lib directory :
https://repository.apache.org/content/repositories/releases/org/apache/nifi/nifi-hive3-nar/1.9.2/nifi-hive3-nar-1.9.2.nar.
https://repository.apache.org/content/repositories/releases/org/apache/nifi/nifi-hive3-nar/1.9.2/nifi-hive3-nar-1.9.2.nar.
Restart NiFi and PutHive3Streaming should be available for use. PutHiveStreaming kept throwing
error not able connect to hivemetastore URI. Like below:
error not able connect to hivemetastore URI. Like below:

Configure PutHive3Streaming Processor
Drag another processor from the menu and choose PutHive3streaming as your processor from the list.
Under Properties tab and add following properties:
Record Reader = AvroReader
Hive Metastore URI = thrift://localhost:9083
Hive Configuration Resources = /usr/local/Cellar/hive/3.1.2/libexec/conf/hive-site.xml
Database Name = default
Table Name = opportunity
Properties:

Relationship termination settings:
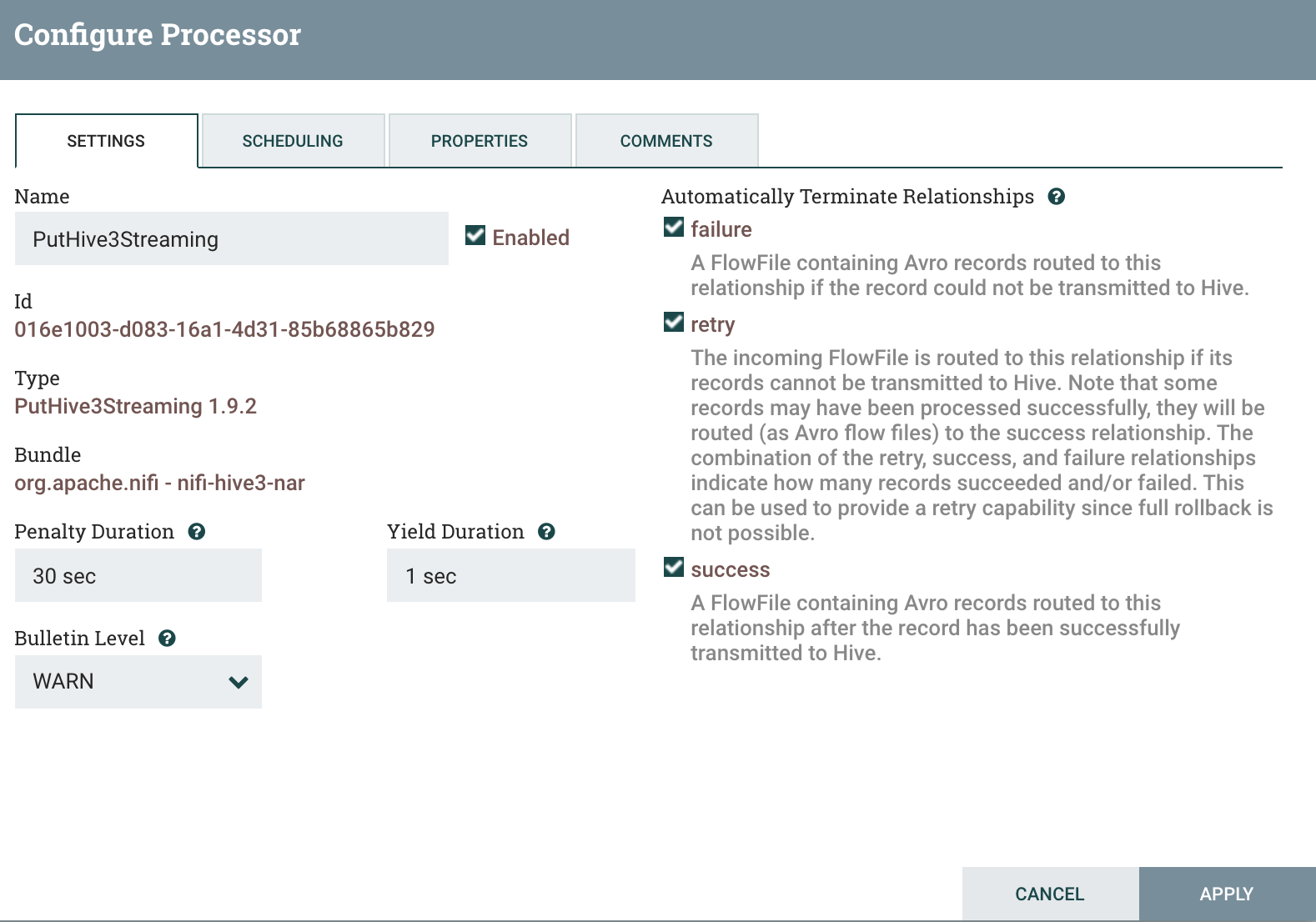
Connect the processor QueryDatabaseTable to PutHive3streaming.
Make sure to check success relationship. Then click on Add/Apply.

Opportunity table schema in Hive:
create table opportunity2
(ID string,
ISDELETED boolean,
ACCOUNTID string,
ISPRIVATE boolean,
NAME string,
DESCRIPTION string,
STAGENAME string,
AMOUNT string,
PROBABILITY string,
EXPECTEDREVENUE string,
TOTALOPPORTUNITYQUANTITY double,
CLOSEDATE string,
TYPE string,
NEXTSTEP string,
LEADSOURCE string,
ISCLOSED boolean,
ISWON boolean,
FORECASTCATEGORY string,
FORECASTCATEGORYNAME string,
CAMPAIGNID string,
HASOPPORTUNITYLINEITEM boolean,
PRICEBOOK2ID string,
OWNERID string,
CREATEDDATE string,
CREATEDBYID string,
LASTMODIFIEDDATE string,
LASTMODIFIEDBYID string,
SYSTEMMODSTAMP string,
LASTACTIVITYDATE string,
FISCALQUARTER int,
FISCALYEAR int,
FISCAL string,
LASTVIEWEDDATE string,
LASTREFERENCEDDATE string,
HASOPENACTIVITY boolean,
HASOVERDUETASK boolean,
DELIVERYINSTALLATIONSTATUS__C string,
TRACKINGNUMBER__C string,
ORDERNUMBER__C string,
CURRENTGENERATORS__C string,
MAINCOMPETITORS__C string )
STORED AS ORC TBLPROPERTIES ('transactional'='true');
NOTES:
SDFC Security Token :
This Token is needed to connect to SDFC via jdbc.
Login to sdfc dev env and reset it, it will send the token in the email attached to the account.
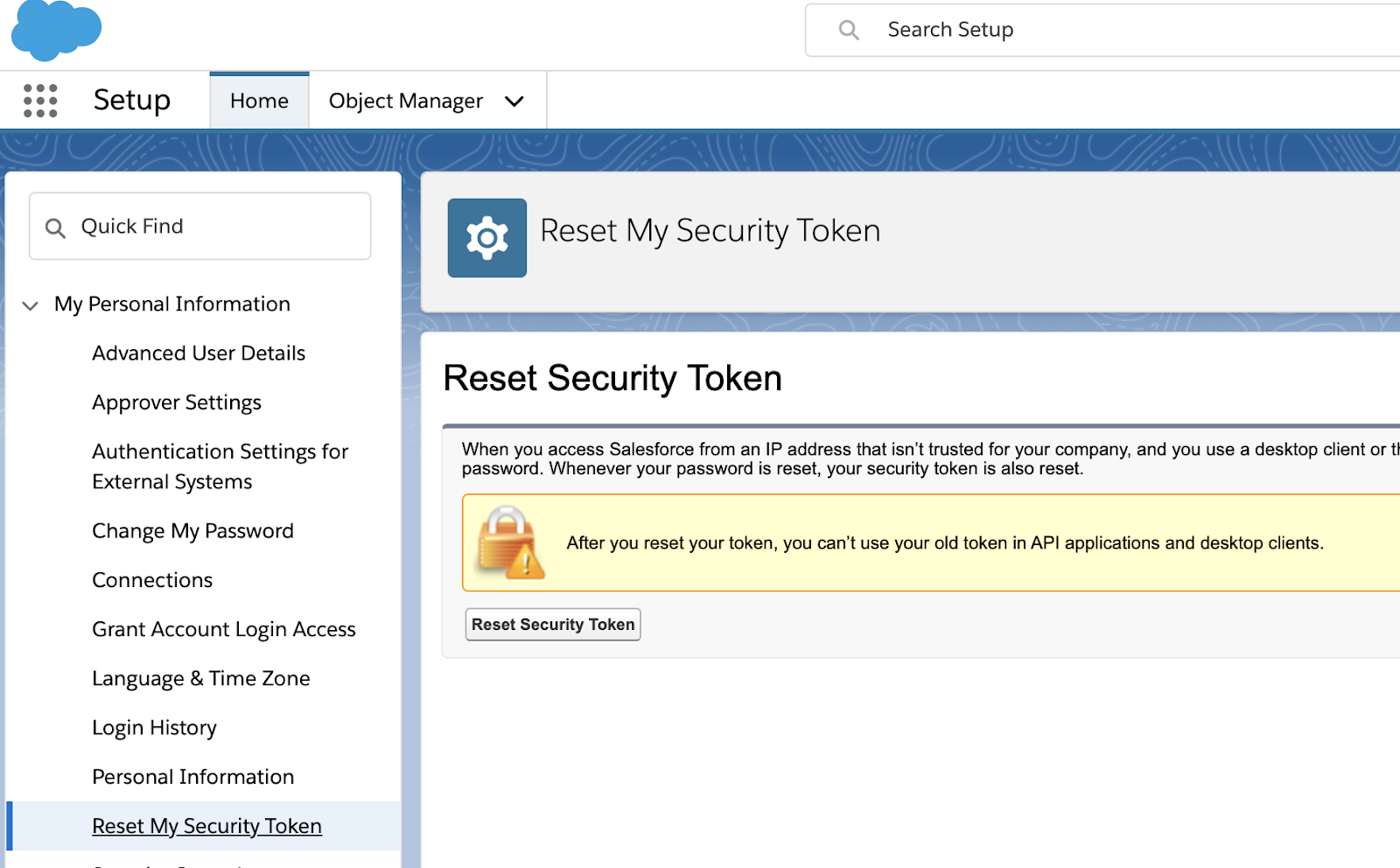
Error while connecting to sdfc without security token.

Hive3 Acid table issues:
Hive version being used was hive 3.1.2. By default table created was not transactional.
This led to the error below.
Error:
2019-11-07 13:25:39,730 ERROR [Timer-Driven Process Thread-3] o.a.h.streaming.HiveStreamingConnection HiveEndPoint { metaStoreUri: thrift://localhost:9083, database: default, table: opportunity2 } must use an acid table.
2019-11-07 13:25:39,731 ERROR [Timer-Driven Process Thread-3] o.a.n.processors.hive.PutHive3Streaming PutHive3Streaming[id=46a1d083-016e-1000-280f-5a026f1ceef7] PutHive3Streaming[id=46a1d083-016e-1000-280f-5a026f1ceef7] failed to process session due to java.lang.NullPointerException; Processor Administratively Yielded for 1 sec: java.lang.NullPointerException
Note:{ metaStoreUri: thrift://localhost:9083, database: default, table: opportunity2 } must use an acid table.
Hive Command line properties set:
set hive.support.concurrency = true;
set hive.enforce.bucketing = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on = true;
set hive.compactor.worker.threads = 1
Only after this creating table with TBLPROPERTIES ('transactional'='true') was successful.
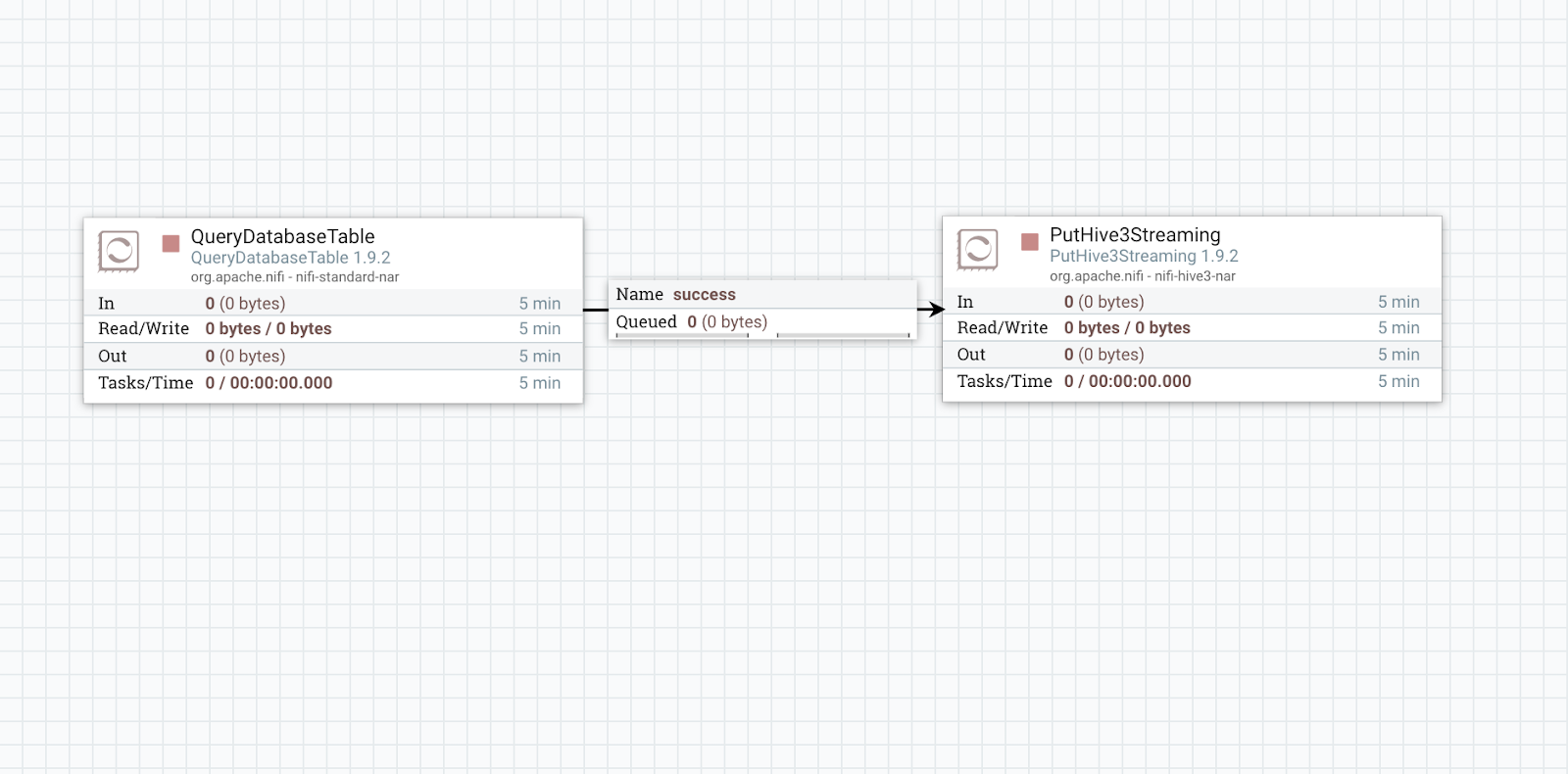
END PRODUCT
Apache NiFi Flow:
HIVE Result:
Beeline > !connect jdbc:hive2://localhost:10000;
0: jdbc:hive2://localhost:10000> select opportunity2.id, opportunity2.accountid,
opportunity2.name, opportunity2.stagename, opportunity2.amount
from opportunity2 limit 10;
opportunity2.name, opportunity2.stagename, opportunity2.amount
from opportunity2 limit 10;


