Tracking Aircraft in Real-Time With Open Source
Tracking Aircraft in Real-Time With Open Source
Use Case: Automatic Dependent Surveillance-Broadcast (ADS-B Analytics)
Software Stack:
- Python 3.10
- Apache Pulsar 2.10.1
- Apache Pulsar Python Library
- Apache Spark
- Apache Flink
- Java JDK 17
- Apache Maven
- SDKMan
- Raspian Linux
Hardware Stack:
- Flightaware Pro Plus Stick (Blue)
- 1090 MHz Antenna and Cable
- Raspberry Pi 4 with 2GB RAM
- USB-C Power Supply

References:
- What is ADS-B? https://www.faa.gov/nextgen/programs/adsb/
- Function Source: https://github.com/tspannhw/pulsar-adsb-function
- Analytics Source: https://github.com/tspannhw/FLiP-Py-ADS-B

Utilizing the Open Source FLiP Stack we can track aircraft overhead with ease! It does require a little bit of hardware and some Python magic. You can build your own at home with a few bits of hardware and some easy open-source software.

Not only are we capturing, transmitting, enriching, and storing this data but we are also contributing back to the world. You can check out my feed at the FlightAware website.

If you think that this looks like some data that you want for your Lakehouse, let’s start ingesting it now. Once you have your hardware configured, see the directions from Piaware. Once you’ve rebooted and everything is running you should be able to see the status of everything running.
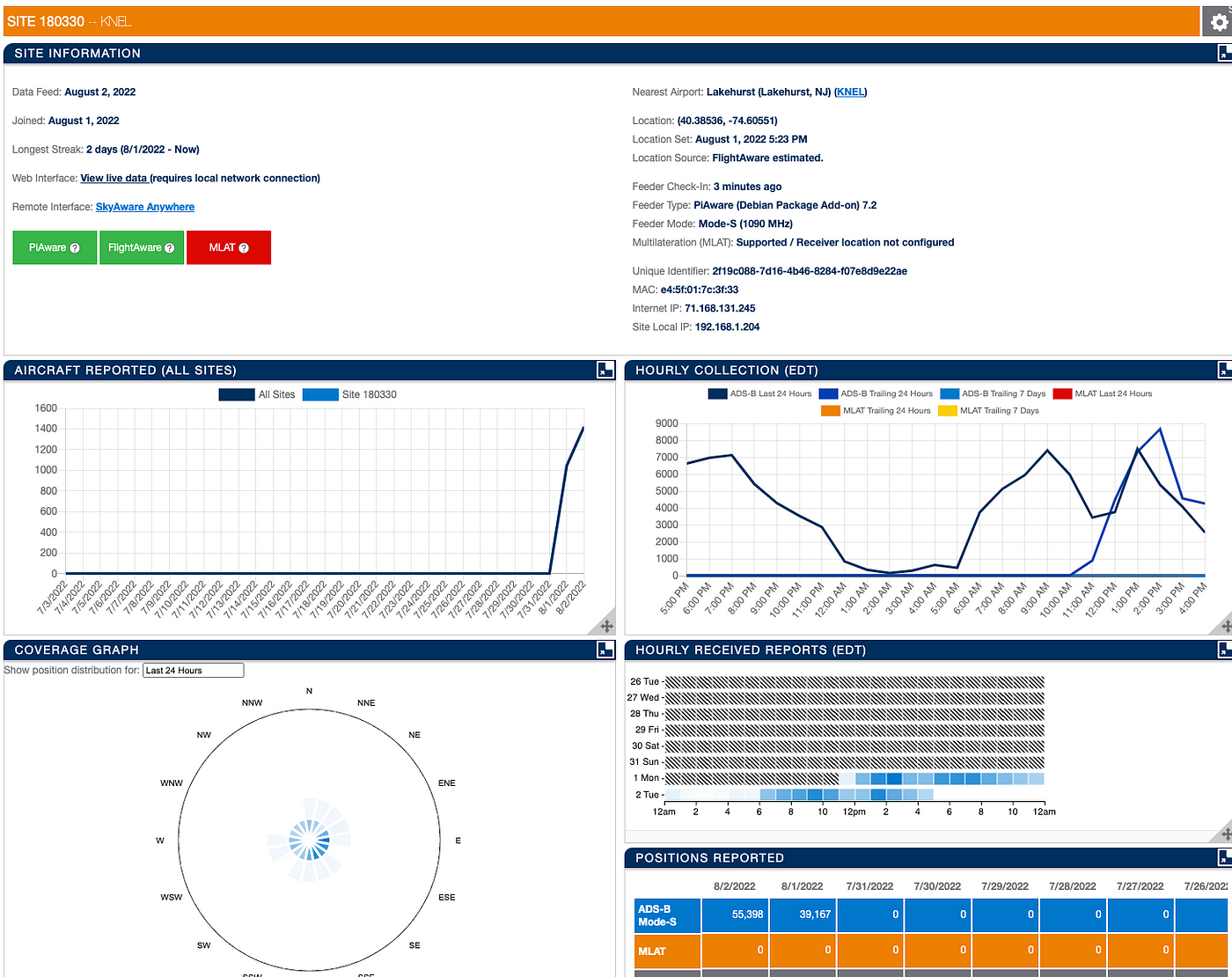
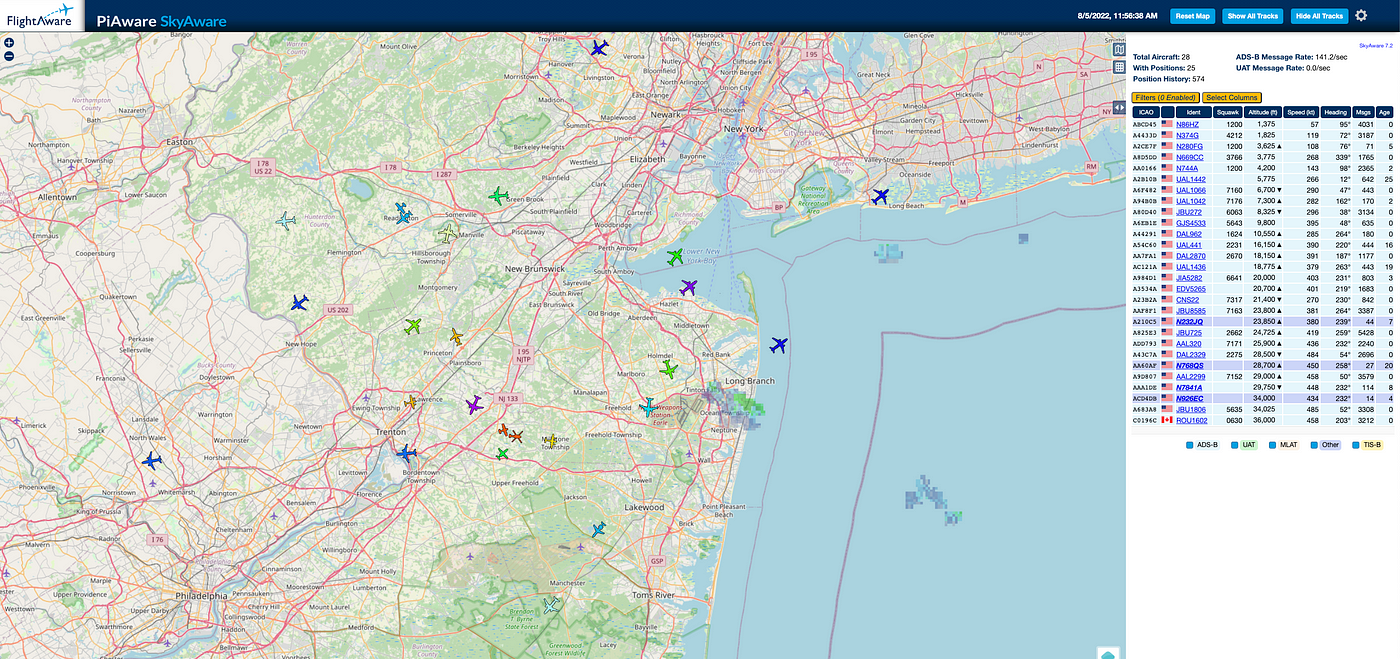
If you want to skip to a video demoing what I did, you can do that.
Step 1
Let’s build out the topics we are going to need for all this raw and processed flight data.bin/pulsar-admin topics create persistent://public/default/adsbraw
bin/pulsar-admin topics create persistent://public/default/aircraftbin/pulsar-admin topics create persistent://public/default/adsblogbin/pulsar-admin topics create persistent://public/default/adsbdead
The first topic is our raw JSON ADS-B data. We may want to use that later so we can let this topic store the data forever, perhaps at some point we will turn on tiered storage and have it automagically stored to object storage on AWS, Google Cloud, or Azure. We also have a topic for clean data, aircraft. Finally, we have a topic for logs output from our processing and one for messages that can be processed. They aren’t dead, since we can raise them like zombies and process them again. Never give up on your data!
The first thing I did was examine the data that was displayed on that pretty local map. By running Chrome in Developer Mode, I saw all the REST Calls made. I see JSON data from simple REST calls. This is where I grabbed what I needed and put it into that handy Python script.
Since we are going to be transmitting, storing, analyzing, querying, and generally sharing this data with different developers, analysts, data scientists, and other people we should make sure we know what this data is.
hex (String optional)
flight (String optional - name of plane)
alt_baro (int optional - altitude)
alt_geom (int optional)
track (int optional)
baro_rate (int optional)
category (string optional)
nav_qnh (float optional)
nav_altitude_mcp (int optional)
nav_heading (float optional)
nic (int optional)
rc (int optional)
seen_pos (float optional)
version (int optional)
nic_baro (int optional)
nac_p (int optional)
nac_v (int optional)
sil (int optional)
sil_type (string optional)
mlat (array optional)
tisb (array optional)
messages (int optional)
seen (float optional)
rssi (float optional)
squawk (optional) - look at # conversion 7600, 7700, 4000, 5000, 7777, 6100, 5400, 4399, 4478, ...)
speed (optional)
mach (optional speed, mac to mph *767)
emergency (optional string)
lat (long optional)
lon (long optional)We need to define a schema with names, types, and optionality. Once we have done this we can build a JSON or Python schema for it and utilize that in Apache Pulsar, Pulsar SQL (Presto/Trino), Apache Spark SQL, Apache Flink SQL, and any consumer that can read a schema from the Pulsar Schema Registry. Data without a contract is just bytes.
- field: hex is ICAO identifier
- field: flight is IDENT identifier
- field: altBaro is the altitude in feet (barometric)
- field: lat, lon is latitude and longitude
- field: gs is the ground speed in knots
- field: altGeom is altitude (geometric)
I looked up what the fields were and made some notes. Squawk values are interesting and that may be of interest to people running SQL later.
Once you get data into a Java class and start sending messages to your aircraft topic, you can pull out the autogenerated schema.
bin/pulsar-admin schemas get persistent://public/default/aircraft
Step 2
Let’s build our Python application to acquire data and publish it to Pulsar! We could choose to use many different libraries as Pulsar supports lots of protocols like Websockets, Kafka, MQTT, AMQP, and RocketMQ. To keep things simple and vanilla I am going to use the tried and true Pulsar protocol and the standard Python Pulsar library. I installed the latest version with pip3.10 install pulsar-client[all]. I did it all since I wanted the FastAvr library, GRPC, Schemas, and other fancy stuff. You can install what you need.
The full Python code is here. I will show you the important bits.
import pulsar
from pulsar import Client, AuthenticationOauth2client = pulsar.Client(service_url, authentication = AuthenticationOauth2(auth_params))producer = client.create_producer(topic=topic ,properties={"producer-name": "adsb-rest","producer-id": "adsb-py" })uniqueid = 'thrml_{0}_{1}'.format(randomword(3),strftime("%Y%m%d%H%M%S",gmtime()))uuid2 = '{0}_{1}'.format(strftime("%Y%m%d%H%M%S",gmtime()),uuid.uuid4())url_data = "http://localhost:8080/data/aircraft.json?_=" + str(uuid.uuid4())response = json.dumps(requests.get(url_data).json())producer.send(response.encode('utf-8'),partition_key=uniqueid)
Then we can run it and start producing raw ADS-B JSON data to our Pulsar topic.
Step 3
Let’s do a simple check to see if data is coming in.
bin/pulsar-client consume "persistent://public/default/adsbraw" -s adsbrawreader -n 0What does this raw data look like?
{'now': 1659471117.0, 'messages': 7381380, 'aircraft': [{'hex': 'ae6d7a', 'alt_baro': 25000, 'mlat': [], 'tisb': [], 'messages': 177, 'seen': 0.1, 'rssi': -22.7}, {'hex': 'a66174', 'alt_baro': 23000, 'mlat': [], 'tisb': [], 'messages': 5, 'seen': 23.6, 'rssi': -27.8}, .. }Well, that is a lot of that. I abbreviated it for the sake of scrolling.
Thanks for staying tuned so far, here’s a cat.

Raw data is nice and all, I can surely have Apache Spark, Flink, Python or others clean it up. I recommend you set up a Delta Lake, Apache Hudi, or Apache Iceberg sink to store this raw data in your lakehouse if you wish.
Architect Note: You could just keep it in Apache Pulsar forever or in Apache Pulsar-controlled tiered storage.
Step 4
I wanted to do this quickly and automagically inside the Pulsar environment so I wrote a quick Java Pulsar Function to split, parse, enrich, cleanup, and route data to a new topic. This will be the cleaned data topic. We could have built this function in Python or Golang as well. I chose Java this time.
Yes, we had to build our own function before we could deploy it in Step 4. Let’s take a quick look at our Java function:
public class ADSBFunction implements Function<byte[], Void> {This means our function takes raw bytes but does not return anything. We don’t have an output specified here since I will dynamically decide where to send the output. We could send to any number of topics on the fly.
context.newOutputMessage(PERSISTENT_PUBLIC_DEFAULT, JSONSchema.of(Aircraft.class)) .key(UUID.randomUUID().toString()) .property(LANGUAGE, JAVA) .value(aircraft).send();At the end of my function, I am going to send the data to a topic (could create these on the fly if we want to send them to different topics). We might want to send all of Elon Musk’s flights to a special topic. We could do those lookups with something like Scylla, I did that for my Air Quality application. I add a key, add a property, set the schema, and send the data. What is nice here is that I don’t have to use formal language to define the schema. I can just build a plain old Java Bean. Keeping it simple and old school, that works for me.
In between that code, I have a helper service that parses that jumble of JSON and pulls out the good bits one aircraft event at a time. It’s pretty simple but nice to keep that code inside a simple function that runs on every event or message that enters the ADSBRAW topic. You will need the Java JDK (11 or 17) and Maven. I recommend you utilize SDKMan so you can run multiple JVMS and tools.
To build the function we just need to type:
mvn package
Step 5
Pulsar makes it easy to add event processing on each topic, so I created a simple one in Java. It’s very easy to deploy, monitor, start, stop, and delete these.
Let’s deploy our function:
bin/pulsar-admin functions create --auto-ack true --jar /opt/demo/java/pulsar-adsb-function/target/adsb-1.0.jar --classname "dev.pulsarfunction.adsb.ADSBFunction" --dead-letter-topic "persistent://public/default/adsbdead" --inputs "persistent://public/default/adsbraw" --log-topic "persistent://public/default/adsblog" --name ADSB --namespace default --tenant public --max-message-retries 5For people new to Apache Pulsar, please note that we have to specify a namespace and tenant for where this will live. This is for discoverability, multitenancy, and just plain cleanliness. We can have as many input topics as we want. Log and Dead letter topics are for special outputs. In this instance, for Java, we have our application stored in a JAR file.
Once deployed, let’s check the status:
bin/pulsar-admin functions status --name ADSBThe results are JSON, which lends itself to DevOps automation. If we wanted we could administrate this with REST or a DevOps tool.
{
"numInstances" : 1,
"numRunning" : 1,
"instances" : [ {
"instanceId" : 0,
"status" : {
"running" : true,
"error" : "",
"numRestarts" : 0,
"numReceived" : 28,
"numSuccessfullyProcessed" : 28,
"numUserExceptions" : 0,
"latestUserExceptions" : [ ],
"numSystemExceptions" : 0,
"latestSystemExceptions" : [ ],
"averageLatency" : 144.23374035714286,
"lastInvocationTime" : 1659725881406,
"workerId" : "c-standalone-fw-127.0.0.1-8080"
}
} ]
}If we wanted to stop it:
bin/pulsar-admin functions stop --name ADSB --namespace default --tenant publicIf we needed to delete it:
bin/pulsar-admin functions delete --name ADSB --namespace default --tenant publicStep 6
Now that the function has processed the data, let’s do a quick check of that clean data.
bin/pulsar-client consume "persistent://public/default/aircraft" -s "aircraftconsumer" -n 0An example of a JSON row returned:
----- got message -----
key:[c480cd8e-a803-47fe-81b4-aafdec0f6b68], properties:[language=Java], content:{"flight":"N86HZ","category":"A7","emergency":"none","squawk":1200,"hex":"abcd45","gs":52.2,"track":106.7,"lat":40.219757,"lon":-74.580566,"nic":9,"rc":75,"version":2,"sil":3,"gva":2,"sda":2,"mlat":[],"tisb":[],"messages":2259,"seen":1.1,"rssi":-19.9}Architect Note: Always set a key when you produce messages.
Step 7
We now have clean data!
Let’s check that data stream with Apache Spark Structured Streaming!
val dfPulsar = spark.readStream.format("pulsar").option("service.url", "pulsar://pulsar1:6650").option("admin.url", "http://pulsar1:8080").option("topic", "persistent://public/default/aircraft").load()
dfPulsar.printSchema()
root
|-- altBaro: integer (nullable = true)
|-- altGeom: integer (nullable = true)
|-- baroRate: integer (nullable = true)
|-- category: string (nullable = true)
|-- emergency: string (nullable = true)
|-- flight: string (nullable = true)
|-- gs: double (nullable = true)
|-- gva: integer (nullable = true)
|-- hex: string (nullable = true)
|-- lat: double (nullable = true)
|-- lon: double (nullable = true)
|-- mach: double (nullable = true)
|-- messages: integer (nullable = true)
|-- mlat: array (nullable = true)
| |-- element: struct (containsNull = false)
|-- nacP: integer (nullable = true)
|-- nacV: integer (nullable = true)
|-- navAltitudeMcp: integer (nullable = true)
|-- navHeading: double (nullable = true)
|-- navQnh: double (nullable = true)
|-- nic: integer (nullable = true)
|-- nicBaro: integer (nullable = true)
|-- rc: integer (nullable = true)
|-- rssi: double (nullable = true)
|-- sda: integer (nullable = true)
|-- seen: double (nullable = true)
|-- seenPos: double (nullable = true)
|-- sil: integer (nullable = true)
|-- silType: string (nullable = true)
|-- speed: double (nullable = true)
|-- squawk: integer (nullable = true)
|-- tisb: array (nullable = true)
| |-- element: struct (containsNull = false)
|-- track: double (nullable = true)
|-- version: integer (nullable = true)
|-- __key: binary (nullable = true)
|-- __topic: string (nullable = true)
|-- __messageId: binary (nullable = true)
|-- __publishTime: timestamp (nullable = true)
|-- __eventTime: timestamp (nullable = true)
|-- __messageProperties: map (nullable = true)
| |-- key: string
| |-- value: string (valueContainsNull = true)
val pQuery = dfPulsar.selectExpr("*").writeStream.format("console")
.option("truncate", false).start()The above Spark code connected to the Pulsar cluster grabbed data from our Pulsar topic and had a table built. As you see setting that schema is a great idea. We can then easily query it as a micro-batch and in this case output it to the console for debugging. We could have also sent that stream somewhere else like S3.
Step 8
Let’s run a continuous SQL query with Apache Flink.
CREATE CATALOG pulsar WITH (
'type' = 'pulsar',
'service-url' = 'pulsar://pulsar1:6650',
'admin-url' = 'http://pulsar1:8080',
'format' = 'json'
);
USE CATALOG pulsar;We create a catalog to connect from Flink to Pulsar.
Let’s take a look at our table.
describe aircraft;
+------------------+-----------------------+------+-----+--------+-----------+
| name | type | null | key | extras | watermark |
+------------------+-----------------------+------+-----+--------+-----------+
| alt_baro | INT | true | | | |
| alt_geom | INT | true | | | |
| baro_rate | INT | true | | | |
| category | STRING | true | | | |
| emergency | STRING | true | | | |
| flight | STRING | true | | | |
| gs | DOUBLE | true | | | |
| gva | INT | true | | | |
| hex | STRING | true | | | |
| lat | DOUBLE | true | | | |
| lon | DOUBLE | true | | | |
| mach | DOUBLE | true | | | |
| messages | INT | true | | | |
| mlat | ARRAY<ROW<> NOT NULL> | true | | | |
| nac_p | INT | true | | | |
| nac_v | INT | true | | | |
| nav_altitude_mcp | INT | true | | | |
| nav_heading | DOUBLE | true | | | |
| nav_qnh | DOUBLE | true | | | |
| nic | INT | true | | | |
| nic_baro | INT | true | | | |
| rc | INT | true | | | |
| rssi | DOUBLE | true | | | |
| sda | INT | true | | | |
| seen | DOUBLE | true | | | |
| seen_post | DOUBLE | true | | | |
| sil | INT | true | | | |
| sil_type | STRING | true | | | |
| speed | DOUBLE | true | | | |
| squawk | INT | true | | | |
| tisb | ARRAY<ROW<> NOT NULL> | true | | | |
| track | DOUBLE | true | | | |
| version | INT | true | | | |
+------------------+-----------------------+------+-----+--------+-----------+
33 rows in setLet’s run some simple queries.
select alt_baro,
gs,
alt_geom,
baro_rate,
mach,
hex, flight, lat, lon
from aircraft;
select max(alt_baro) as MaxAltitudeFeet, min(alt_baro) as MinAltitudeFeet, avg(alt_baro) as AvgAltitudeFeet,
max(alt_geom) as MaxGAltitudeFeet, min(alt_geom) as MinGAltitudeFeet, avg(alt_geom) as AvgGAltitudeFeet,
max(gs) as MaxGroundSpeed, min(gs) as MinGroundSpeed, avg(gs) as AvgGroundSpeed,
count(alt_baro) as RowCount,
hex as ICAO, flight as IDENT
from aircraft
group by flight, hex;
We can do basic queries that will return every row when it arrives or aggregate them.
Step 9
We did it. Let’s start streaming our little dream stream.

Thanks for staying for the entire app building. I hope to see you soon at a meetup or event. Contact me if you have any questions or are looking for other apps built powered by FLiPN+.

For additional resources to build more advanced apps:
- https://flightaware.com/adsb/piaware/build/
- https://github.com/adsbxchange/dump1090-fa
- https://flightaware.com/adsb/piaware/build
- https://flightaware.com/adsb/piaware/build/optional#piawarecommands
- https://dzone.com/articles/ingesting-flight-data-ads-b-usb-receiver-with-apac
- https://globe.adsbexchange.com/
- https://community.cloudera.com/t5/Community-Articles/Ingesting-Flight-Data-ADS-B-USB-Receiver-with-Apache-NiFi-1/ta-p/247940
- https://elmwoodelectronics.ca/blogs/news/tracking-and-logging-flights-with-ads-b-flight-aware-and-raspberry-pi
- https://github.com/flightaware/piaware
- https://github.com/erikbeebe/flink_adsb_stream
- https://github.com/erikbeebe/flink_adsb_querystate
- https://github.com/openskynetwork/java-adsb
- https://openskynetwork.github.io/opensky-api/rest.html
- https://github.com/openskynetwork/opensky-api
- https://opensky-network.org/my-opensky
- https://dev.to/tspannhw/tracking-air-quality-with-apache-nifi-cloudera-data-science-workbench-pyspark-and-parquet-28c
- https://openskynetwork.github.io/opensky-api/rest.html
- https://github.com/tspannhw/airquality
- https://www.faa.gov/air_traffic/publications/atpubs/atc_html/chap5_section_2.html
- https://aviation.stackexchange.com/questions/60747/what-are-all-the-squawk-codes
- https://en.wikipedia.org/wiki/List_of_transponder_codes
- https://github.com/briantwalter/spark1090
- https://youtu.be/0LMOglFN8ZA


